
A New Paradigm for Collaboration Between Data Scientists and Subject Matter Experts Can Improve Risk Model Performance and Explainability
The financial crimes risk and compliance industry makes use of software applications to assign risk labels to people and organizations. Often these labels are straightforward: a person was “arrested” for a specific crime or a company is on a “sanctions” list. But some risk labels are more ambiguous, with threats such as “domestic terrorism” or “foreign malign influence” leaving too much room for subjective, and therefore inconsistent, interpretation. This ambiguity increases when screening for signals from news and other unstructured data, where the vagueness of natural language comes into play.
For simpler AI models, subjectivity is less of an issue. To train an image classifier, it is conceptually easy to have a human tag a picture with “cat” or “no cat” as part of the training process. But even then there remains a problem: should the human tag a lion or a tiger as a cat? What about a drawing of a cat? Machines are literal, for better or for worse, and need to be told exactly what to do. Specific definitions are needed that are understood by both the trainer (the labeler) and the trainee (the algorithm) alike.
In classifying different types of risks, misalignment of risk definitions between humans and machines can lead to bad outcomes. The investigator may be swamped in false positives, or not even understand the evidence behind the risk label. Risk labels need to be accurate, and the data scientists who develop the risk models behind those labels have a responsibility to both the investigator and the subjects labeled with risk to be as precise as possible. The confusion caused by vague risk definitions can lead to incorrect and inconsistent conclusions that weaken the case of any investigator.
The standardization of “risk cards” is one way to reduce subjectivity in risk assessments and facilitate common interpretation of different categories of risk. Risk cards can serve to “train the trainer”, providing a mechanism for subject matter experts to contribute directly to the work of data scientists to define common risk models. In analogy to “model cards”, which are used to provide responsible transparency into how machine learning models work, risk cards are meant to focus in detail on operationally defining the objective task for a risk-labeling model. Most risk models will never be perfect, hence the need for transparency and explainable models, but we can always do better as teachers to train our models cleanly and, in this spirit, risk cards are meant as a teacher’s guide.
But who should be creating these teacher’s guides? For proper division of responsibilities, who should be authoring the risk cards and who should be training the models? While Quantifind has a large team of world-class data scientists who can build high-performance models given an objective, we do not have domain experts in every risk typology that we model. Yet we do have many collaborative partners in financial services, government, and law enforcement who are experts in their distinct domains. These domain experts, not only the data scientists, should play a substantial role in helping define, or at least review, the risk definitions in question. There is also potential to further operationalize an even wider realm of passionate experts in the non-traditional partner space, including NGOs (non-governmental organizations), university research centers, think tanks, and investigative journalists.
Even if the model details are not provided, a risk card should present sufficient context, training examples, and candidate features useful for building risk models with high precision and coverage for specific risk labels. These risk labels can be as diverse as, for example, “Natural Resource Exploitation”, “Weapons Trafficking”, or “Scam”. Risks need not be limited to criminal or malign activity, and can cover broad categories including National Security, Regulatory Risk, Reputational Risk, Financial Health, and ESG Risk (environmental, social, and governance). All of these risks are intertwined in practice and treating them together allows us to account for appropriate distinctions and correlations.
Risk Cards should include the following key elements:
- Definition: A simple, few sentence operational definition that will be read by the human responsible for labeling training data. This can be accompanied by a review of prior existing definitions, details on what is not included in the definition, and a justification for why certain groups, say banks or intelligence agencies, might care about the risk.
- Entities and Networks: To really define the objective of a supervised model you need training data. In this case, that means “naming names” of people and organizations that do (and don’t) deserve that label. For example, one could create a list of 100 or more prior known “Drug Traffickers” as found in news articles. Exploring the list will train both the models and the trainers on what is common and what are edge cases that need to be considered. By comparison, most law enforcement agency reports meant to communicate risk typologies do not list examples and instead they ineffectively focus on justifying the need to solve the problem in abstract, non-operational terms.
- Topics and Terms: The Risk Card should summarize features that need to be considered by any topic model meant to capture the risk in question. For example, a Risk Card on “Wildlife Trafficking” should detail as many of the precise terms for trafficking-related animal products as possible to ensure completeness of the ultimate model. In this case, we may discover “chuashanjia” (meaning Pangolin scales) as a new, non-obvious term that should be included in the Wildlife Trafficking feature set. Or, for “Natural Resource Exploitation” we may discover “galamsey” as a useful term, not just “illegal mining”. Of course supervised or unsupervised topic expansion techniques can be used to suggest terms and expand upon seed terms for this task. But to be useful, the Risk Card does not need to provide the detailed structure of the eventual topic model, only the terms and features that complete models must ultimately consider.
- Sources and Signals: Each risk typology has its own niche set of data sources that need to be evaluated by any data scientist trying to achieve reasonable coverage in their model. New, potentially relevant data sets are emerging every day for most risk typologies, and it is difficult for most risk screening practitioners to keep up. These data sets should be listed in the Risk Card, along with “signals” and other potential model features that may indicate the presence of the threat when considered as a whole. These inferential signals are sometimes referred to as “BOLO” (Be On the Look Out) in law enforcement, and these human, intuitive signals can be translated into risk labeling as well.
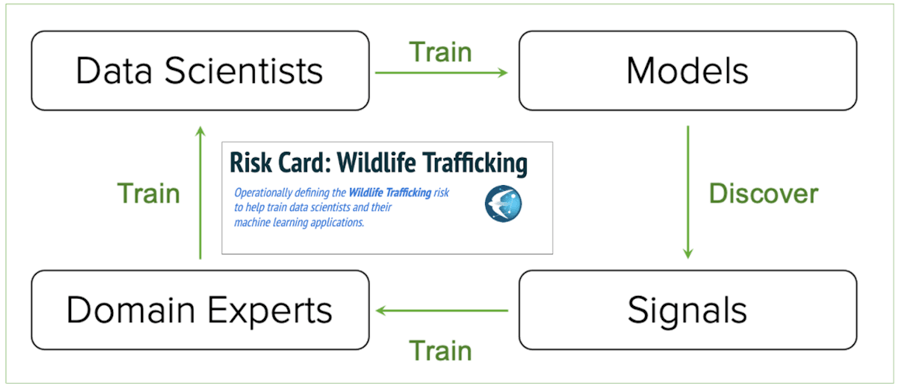
Quantifind’s role is to help channel this human expertise into effective augmented intelligence and machine learning processes that enable effective and complete risk models. The final goal is a feedback loop wherein domain experts train data scientists who train models that discover signals and, in turn, those signals can complete the loop by training the domain experts as the risk environment evolves dynamically. The Risk Cards then present a means by which we can help share discovered predictive signals, and domain expertise, across the walls of public and private silos.
At this phase, Quantifind is developing its own Risk Cards internally with our customers and partners, but we would welcome the chance to collaborate and share with interested partners. Please contact Quantifind for details.
