
AI can be used to automatically exclude questionable content from risk assessments without throwing the baby out with the bathwater
A bank’s approach to AML increasingly includes continuous monitoring for negative news about its clients in order to better manage regulatory and reputational risk. But disinformation has proliferated throughout the media landscape, ranging from biased opinions and sensationalism disguised as news to intentional deception and outright slander. How should fake news be accounted for in adverse media screening solutions? It turns out that the same machine learning-based technologies used to detect and characterize adverse media can also be applied to account for these dubious sources and articles while still mining for what valuable information they may hold.
“Fake news” comes in various flavors, differentiated largely by the intent of the author, and they warrant different treatment:
1. Fake, false, or fabricated.
Literally fictional news including disinformation and propaganda, written with a primary objective to deceive its readers
2. Misleading content.
Content that is unintentionally biased or inaccurate, written to persuade or inform but done so without regard for factuality
3. Clickbait.
Content written explicitly to gain attention and readers, which can tend to be hyperbolic and exaggerated.
4. Satire and parody.
Content written to entertain with humor, with an assumption that the reader is in on the joke and understands that the author is not presenting the content as factual.
5. Opinion and editorial.
Content written to express opinion, which may or not be represented to the reader as such.
The Onion, as a satire outlet, is arguably among the “fakest” of news sources and provides an obvious example of how fake news has the potential to impact automated risk assessments if not addressed. A story about “aspiring felon Matthias Winnow” and the inspiration that Paul Manafort provided to him in his criminal endeavors is a satirical piece, but could certainly cause problems for a real Matthias Winnow at his bank if their screening processes don’t factor for fakeness.
But while fake news clearly has a presence in the information supply and can lead to misinformed risk assessments, there is nevertheless potential value to be mined there, particularly on domains covering news beyond that of more traditional sources.
Automating fake news detection
 Given a specific news article, there are four distinct methodologies that can be used to determine the reliability of its content:
Given a specific news article, there are four distinct methodologies that can be used to determine the reliability of its content:
Source-based. This methodology relies on the fact that some sources are more reliable than others. Sources that have a documented history of publishing fake or unreliable content can be flagged to alert a reader to search for corroborating evidence. In some circumstances, it is necessary to remove a source altogether because unreliable information outweighs reliable information.
Text-based. This methodology identifies patterns in the text of an article that are likely to appear in fake content. Fake news is often curated to target a specific audience and to propagate a particular ideology. For that reason, fake content will often have different language patterns than fact-based reporting and an algorithm can identify those patterns. Text-based detection will generally rely on features generated from the syntax, lexical patterns, or psycholinguistic language of an article.
Social network-based. This methodology utilizes data collected around the interactions and sharing of an article through social networks. Specific propagation patterns often vary between fake and fact-based news. By analyzing the patterns around who shares content and when, an algorithm can detect articles that are likely to be unreliable.
Content-based. This methodology aims to verify specific claims made in an article to determine if they are likely to be true. Similar to how a human would fact check an article by looking for substantiating evidence from other sources, this approach identifies claims in an article and looks for information that can verify that claim.
The Quantifind approach
Quantifind’s unique expertise is founded in leveraging artificial intelligence to derive insights from unstructured text data found across vast public datasets. Combining source-based and text-based classification, we are able to significantly broaden the range of useful sources and data while reducing the impact of fake news in our adverse media screening.
Source-Based Screening
The first phase includes source-level and domain-level screening. Our internal research found over 1500 domain sources of fake news, misinformation, and heavily biased content. This research leveraged professionally curated lists of unreliable media sources, as well as our own analyst reviews. Between 1-3% of our news archive content is attributable to unreliable sources. By combining data-driven analysis with manual analyst review, Quantifind is able to identify the most harmful sources of fake news and filter them from our risk alerting. Our targeted review process identified 52 domains that are the worst propagators of fake and unreliable content and removed them completely from our screening results.
Document Level Screening
The next phase in the process is document-level screening using a text-based methodology. There are a few advantages to this approach that complement the source-based implementation. Not all sources fall into a binary label of reliable and unreliable; there is a spectrum at the article level where a single source may have a mixture of thoroughly fact-checked news content and less reliable content. We don’t want to remove all results from a given source if only a small percentage of the content is unreliable. In these cases, Quantifind can identify the specific articles that are a problem instead of labeling at the source level only.
Another motivation for document-level analysis is the risk of domain name changes or URL spoofing. Sites propagating fake news are known to change their domain once they’ve been identified by a fact-checking outlet. URL hijacking is another known tactic for disinformation to appear to be legitimate news from credible sources. The advantage of document-level detection is that it evaluates the content and not just the source.
Quantifind has developed AI-driven models and algorithms to classify documents based on textual features. The first focuses on identifying editorial and opinion pieces that are less relevant to adverse media screening. Using a rules-based approach to parsing article URLs, we were able to characterize over 4,000 documents as opinion pieces with greater than 90% precision. This strategy can be used to label certain documents as opinion so that an investigator is aware of that context when reviewing the article.
The second identifies patterns within features of the articles’ text that distinguish reliable vs. unreliable content. Our model utilizes syntax features such as number of words per sentence and readability, lexical features such as types of pronouns used, and psycholinguistic features such as the amount of positive or negative emotionalism. The power of a machine learning algorithm is that by combining many features with slight predictive power it can discover accurate patterns that would otherwise be unnoticeable.
AI-Powered Fake News Detection
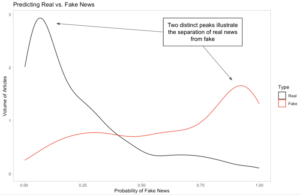 Quantifind is able to correctly characterize fake news on a representative set of labeled training data. These results illustrate how patterns can be detected to distinguish between reliable and unreliable content. For this example, the “fake” category includes content that is fake, heavily biased, unreliable, or clickbait.
Quantifind is able to correctly characterize fake news on a representative set of labeled training data. These results illustrate how patterns can be detected to distinguish between reliable and unreliable content. For this example, the “fake” category includes content that is fake, heavily biased, unreliable, or clickbait.
After combining a group of relevant features the model was able to differentiate the real and fake content. The model was much more likely to give real content a low probability of being fake.
Quantifind will eventually be able to label unreliable content at the document level within our investigation interface. Doing so boosts efficiency by removing false signals found in untrustworthy claims, leaving the investigator with only the most relevant alerts.
With thousands of articles posted on an hourly basis, across continents and languages, there is a wealth of data to which intelligent analytics can be applied to help detect potential risks of financial risk and crime. Quantifind has developed its search algorithms explicitly to work with all types of public content to leverage its value while preventing the use of unreliable information.