
Using machine learning to discover signals that categorize companies into high-risk areas.
A common use case at banks and other financial institutions is to discover in what line-of-business an organization is actually involved. This “know your customer” context is always good to know, but there are certain high-risk areas that banks are particularly sensitive to, including those with unclear or evolving legal status, such as cryptocurrency or marijuana. Banks often create policies against these industries, incentivizing organizations to hide their true line-of-business, or at least not be blatant about it. Even when an organization is being honest about its business, there may be multiple areas a single company engages in, and the category that is “registered” is cherry-picked by the company to avoid exposure.
At Quantifind, one of our methods allows us to transparently reveal a line-of-business via links: explicit evidence or URLs that reveal the activity of interest. In one case, we were able to discover a supposed cookie shop that was selling cookies for a large mark-up and discreetly offering marijuana “gifts” on the side. While this approach (and those relying on registry lists) can cover a lot of ground, another approach is to use machine learning over a large set of training data to infer when a company is involved in a certain category based on available signals. Even when an explicit link to news or list does not exist, there are many other potentially predictive signals available, including the location of the company, the people working at the company, the followers of the company on social media, etc.
More obviously, we can consider the name of the company. In other words, given only the name of a company can we predict their line-of-business? Clearly, the answer is yes: it does not take a sophisticated AI system to tell you that “The Marijuana Company, Inc.” is in fact a marijuana company. But the more difficult challenge is to be more complete: for less obvious names can we make a model that creates a quantitative prediction of the probability that the company belongs in a particular category?
Of course a company in an illicit industry may have a deceptive front or shell identity (another interesting classification problem for another post) or use a name that is so obscure or common as to eliminate recognizability (ACME, Inc.). But for many companies, the name is a point-of-exposure: if they want people to buy their product, then they have some pressure to be descriptive. The reason street code words are used in the drug industry is to promote informational asymmetry where, essentially, the consumer knows what it is, but law enforcement may not. The companies cannot just use arbitrary words, there needs to be a somewhat consistent and repeated language, however fluid. For big enough industries and marketplaces, patterns will emerge.
For this post, we will focus on the category of “marijuana” but the methodology easily transfers to any other high-risk category in a fully automated fashion. Categories like bitcoin, payday lending, and ponzi schemes all telegraph signals in a similar fashion. It should be noted that marijuana is legal in an increasing number of states, and we are agnostic as to what policies get enforced at financial institutions. We chose this example because it is currently relevant and on the interesting edge of legality.
METHODOLOGY AND RESULTS
The goal of our model is to determine the terms in a company’s name that are predictive of the company operating in the marijuana industry.
It is not extremely difficult to get some training data for this task. There are an increasing number of marijuana registries and, in principle, you would just need to pull one of these along with a reference data set to compare against, and build an initial model. We have the ability to do this, but we also have a more scalable approach. To dynamically generate a training set for any category, we can find all specific company entity names that predict, above some threshold, the presence of the words for that category in a large corpus of news documents. Then we can compare the terms in these company names to the prevalence of those same terms from all entities mentioned in the entire (unfiltered) set of news articles. In this way, with just a couple queries of our system, we can immediately generate predictive terms for any category. For example, we could discover what terms bitcoin companies use in their names just from the news, as opposed to digging up some bitcoin registries from somewhere which is labor intensive, incomplete, and eventually stale.
This approach requires high quality named entity recognition (NER) to only extract strings representing organizations and not other random phrases. Ideally, the query would also return only companies that potentially sell marijuana and exclude law enforcement and other government agencies, e.g., the Drug Enforcement Agency (DEA). In practice we can add another classifier to do this as well, but for the purposes of this blog, we will leave these in and consider this in the interpretation of the results. As long as we keep these exceptions in mind, or add a “government” classifier in tandem, we can account for this source of noise.
Using this approach, we can now generate a ranked list of terms that are predictive of a marijuana company, essentially ranking them by the conditional probability P(marijuana|term), or the probability that a company is weed-associated given that a particular term is in the name. The resulting data is shown below:
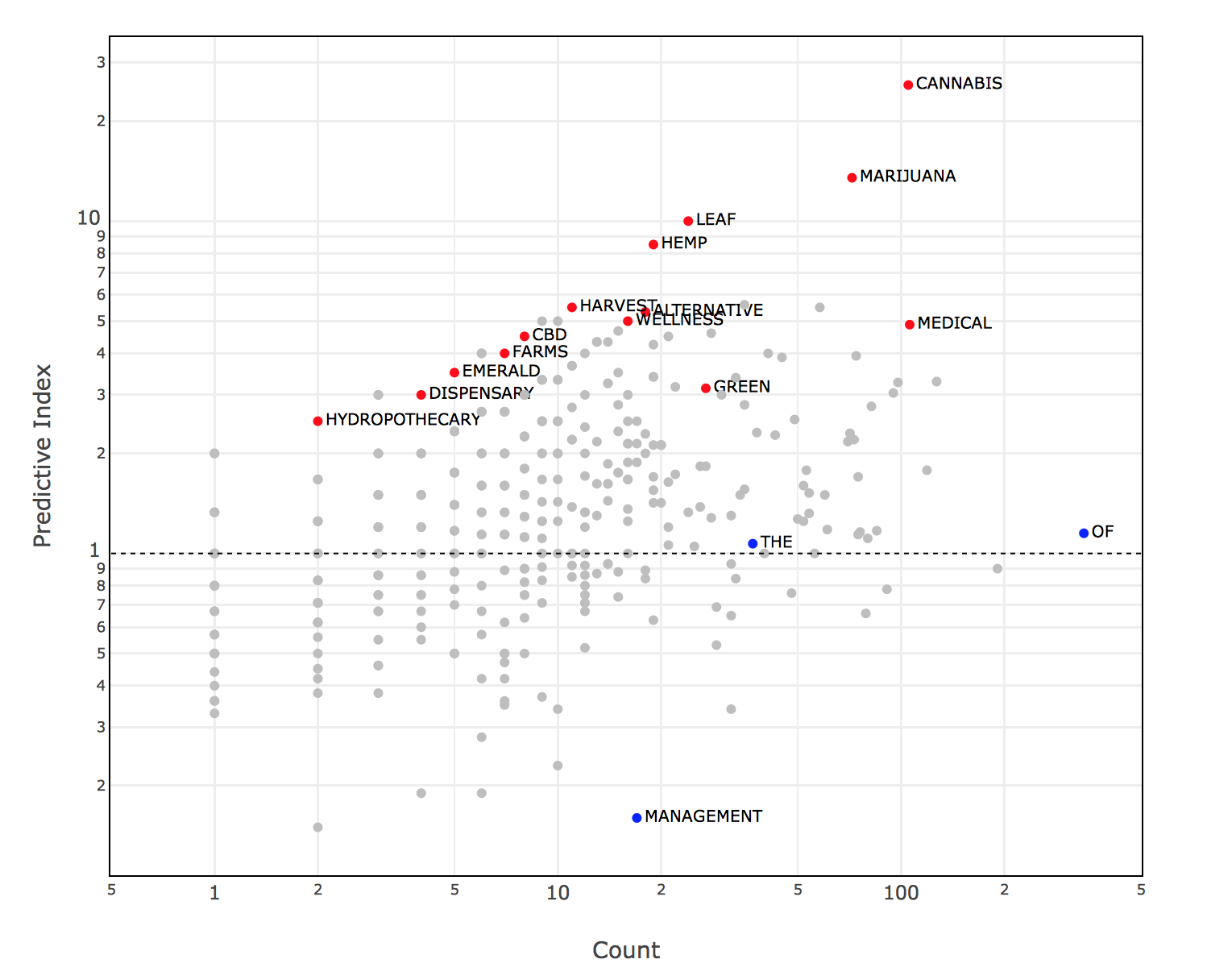
The y-axis is the Predictive Index. The exact definition and relation to the conditional probability does not matter much, but the higher a word is, the more predictive of marijuana it is and vice versa. The x-axis is the size of the sample for that term, or the number of organizations in our small marijuana news sample that hit on this term. For example, the term “HARVEST” is predictive to a certain level, but has fewer organizations with it in the name than “GREEN”, which is less predictive but bigger. The red points represent predictive terms we have decided to call out. Note that “CANNABIS” is judged as more acceptable than “MARIJUANA” and is thus bigger and at least as predictive. The gray dots represent other terms, some predictive, some not, that we have redacted for the sake of focus and not sharing everything. The blue dots are just negative results for the sake of illustration: it makes sense that the common terms “THE” and “OF” are non-predictive, thus near the neutral horizontal dashed line of 1. Whereas the term “MANAGEMENT” is anti-predictive and under-indexes on marijuana related companies when compared to a broader sample.
Here is a table showing the some of the red predictors from above, categorized into certain classes manually and annotated with real example company names that are all in fact marijuana-related:
| Class | Terms | Example |
|---|---|---|
| Synonym | Marijuana | Medical Marijuana, Inc. |
| Synonym | Cannabis | Aurora Cannabis |
| Synonym | CBD (Cannabidiol) | Diamond CBD |
| Synonym | Hemp | Industrial Hemp Manufacturing, LLC |
| Agricultural | Farms | Double Diamond Farms |
| Agricultural | Leaf | Urbn Leaf |
| Agricultural | Green | Green Rush |
| Agricultural | Emerald | Emerald Health Therapeutics |
| Agricultural | Harvest | Indoor Harvest Corporation |
| Related | Hydropothecary | The Hydropothecary Corporation |
| Related | Dispensary | Nevada Dispensary Association |
| Location | Humboldt | Humboldt Cannabis College |
| Medical | Wellness | Wellness Connection of Maine |
| Medical | Alternative | Alternative Herbal Health Services |
When playing the prediction game, some of these are obvious (e.g., Aurora Cannabis), but others are less so (Diamond CBD, Green Rush, Urbn Leaf, or Wellness Connection of Maine). At least they are harder to imagine a definitive answer, without help from a model. For these, we can provide value by predicting whether or not the name alone constitutes sufficient evidence of being related to marijuana. A good model ensures efficiency because, even if manual effort is needed for curation and ultimate verification, the model enables a “shortlist” prioritization process that can be more complete, consistent, and up-to-date than any human-based or list-based process would be. As is the goal with any model, this removes unnecessary subjectivity and increases throughput significantly.
We present these signals only to demonstrate a proof-of-concept, and our more complete production model includes many more factors. For example, certain substrings are also predictive, which can also be helpful in email and website name classification which lack spaces. “Canna” for example can easily be identified as a signal: CannaRoyalty Corp., The Cannabist, Cannabix Technologies, Canna Clinic, etc. Similarly, this would let us identify Leafly, Weedmaps, etc. Also, when evaluating user names and associated text for more informal code words, the language gets closer to street language, and we discover colorful terms like: kush, berrycough (a strain), diamonds, red eye, high, mary jane, headband, scooby snax, and many others. These words may be too informal for official company names, but not for terms that occur on dark web markets and other online forums. Finally, we can also train on internal data of financial institutions. For example, which companies are associated with employees bringing in bags of money that “smell like weed” as is often documented in internal reporting.
Ultimately, the power that Quantifind offers financial institutions is to create exposure review processes that are more complete, efficient, and up-to-date than standard methods as the relevant market patterns evolve. In contrast to simple list-checking approaches, which are necessary but tend to be limited and quickly grow stale, our algorithms can cast a much larger net and fluidly adapt over time. The model can dynamically learn new signals over time by using training data that is bootstrapped from queries over dynamic, continuously updating feeds of external data. The result is that potential risks are caught quickly and the client can have confidence that all predictive signals have been screened.
If you are interested in learning more, please contact us.
