
“It is the job of the IC (Intelligence Community) to analyze data, connect disparate data sets, apply context to data, infer meaning from data, and ultimately make analytic judgments based on all available data.”
This is the first sentence of a whitepaper the Office of the Director of National Intelligence (DNI) released last year summarizing its AIM Initiative: A Strategy for Augmenting Intelligence using Machines. Motivated by U.S. government fears of falling behind in the international AI arms race, especially to China and Russia, the document is part of an effort to establish an Intelligence Community wide framework that leverages recent advances in artificial intelligence and machine learning.
The italicized phrase from that first sentence, “connect disparate data sets,” has many potential meanings: It can mean setting up the technical plumbing in a common platform that lets data live in the same environment. It can mean enabling data to be shared while also respecting necessary privacy and access constraints.
It can also mean breaking down bureaucracy that prevents data in separate silos from gainfully interacting. This may be the IC challenge of our times. From 9/11 up to Covid-19 today, it has been repeatedly brought up in the response to national emergencies, in which various agencies have struggled to effectively share data.
At Quantifind we are focused on the intelligence facet of the data integration problem. Even if bureaucracy is eliminated, data is shared, and privacy is respected, there remains a more pressing problem: The data itself is usually not easy to integrate due to non-unique identifiers. In this article, we will outline some ways in which Quantifind is leveraging AI solutions to address this critical issue—creating a “data glue” to seal any IC gaps.
The Need for Probabilistic Data Linking
Sometimes merging two data sets is easy, because two tables have a unique key column in common. Simply merge the tables on that column and the task is done: You now have extra features for your model and whatever other enrichment value the two datasets bring to each other. The problem is that you usually do not have this magic column by which tables can meaningfully talk to each other. Unique standardized identifiers are rare, especially when data comes from public sources in the wild.
In Quantifind’s case, we are typically given a name (of an individual or organization) and asked to find matching records in a large number of other disparate data sets. Sometimes we may have some location information or other helpful metadata, but there is no shared unique identifier like a social security number, or even an email address, available. Without unique identifiers, connecting data sets by name or other limited information is technically impossible at 100% confidence.
However, an intelligent algorithm does not need 100% confidence to make progress and effectively augment the intelligence of a human. Therefore, we approach the problem from this probabilistic perspective. Each entity in one database has some probability of being the same entity in the other database, and it is our job to assess this probability in the best way we can.
Essentially, Quantifind trains its machines to follow similar patterns to those that humans follow when they are assessing link confidence, but allows them to do it at superhuman levels. Thus, the results are inherently explainable (not black box) to a human. When manually merging or searching data, investigators are unfortunately still using crude techniques and labor intensive searches, and inconsistently guessing whether somebody is the “same guy” or “same company”. As with all classic AI use cases, we are able to take the drudgery and inconsistency out of potential link scouring, and risk screening, through automation.
Creating a Novel Toolbox for Entity Linking
The task of Named Entity Linking (NEL) is core to the data fusion and disambiguation problem, and Quantifind has developed world-class algorithms that can assign these confidence levels, or link probabilities, at scale. As described in a recent article, one core tool we have built is “name rarity” assessment, which automates the fact that “John Smith” matches are less probable than “Dweezil Zappa” matches. We have extended this to a global perspective and are able to estimate the number of individuals in any country with any given name using a global name rarity solution.
The Quantifind technology is also adept at name stemming, soft matches, nicknames, aliases, and understanding name variants across languages. For organizations, we can predict which industry an organization is in, which is useful for both risk assignment and linking. Beyond names, we can extract more context with advanced Named Entity Recognition (NER) from unstructured documents and boost link confidence when other co-occurring data elements line up, such as locations, related entities, etc.
The linking approach can be applied in a “one-to-many” mode, as it occurs in our Entities product, where a name is entered and linked to many disparate data sets, or in “many-to-many” mode, where we can apply a batch operation to screen entities in a data set, such as a customer record database, against all of the public data sets under our control. This can be applied between any two datasets as we demonstrated in an application merging election contribution records with criminal records.
The result can be considered a sparse matrix where the rows are entities from data set A, columns are entities from data set B, and entries are probabilities of equivalence. This can be viewed as a form of probabilistic enrichment and is amenable to techniques in graph theory where edges in a network are not always completely certain. The approach is not limited to entities types of individuals and organizations; it can also be applied to a wide class of other data types (locations, products, materials, times, currencies), where the same soft-matching and confidence-building approaches also apply.
Data Glue as Advanced Entity Resolution
Stepping back, what we are doing with our entity-linking technology is providing a new kind of data glue, connecting data sets that are tricky to connect because of their inherent structure.
To draw an analogy, imagine if you took away the “merge” or “join” operations in SQL. Tables would not be able to interact. Features would be lost from models, degrading performance. Immense value would be lost in any data rich application. This may seem like an academic thought experiment, because merge operations are trivial. But, for large classes of datasets, they are not trivial and immense value is being lost because it is simply difficult to unify certain data sets which are, in fact, possible to merge. By not using these probabilistic enrichment techniques at scale, critical fields and features for models will be missed, and “whole” will be prevented from being more than the sum of the parts.
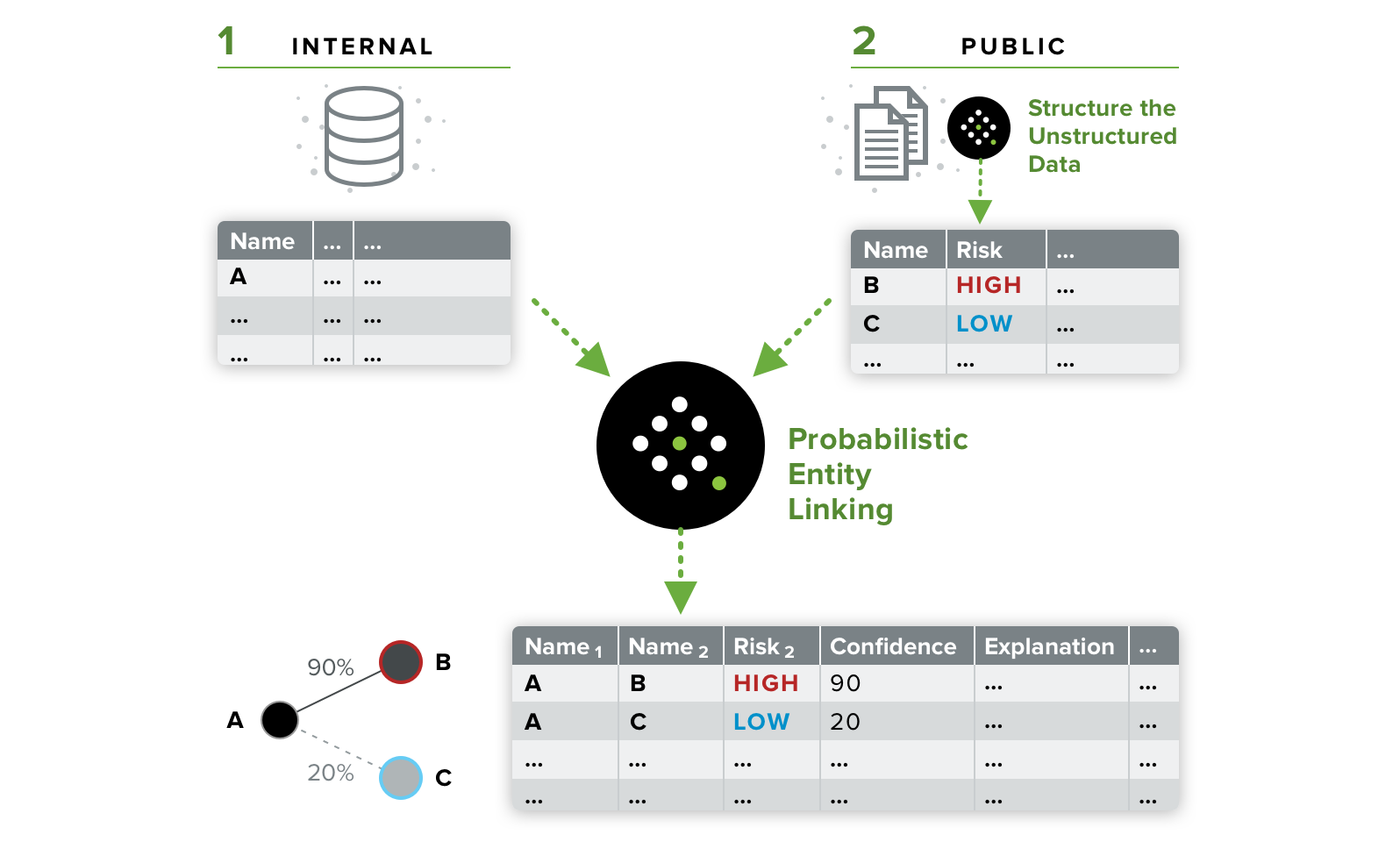
The figure above shows Quantifind’s data alignment process. First, external unstructured records are turned into structured records and, second, they are resolved against the internal data records, with varying levels of confidence depending on available information. The bottom of the figure shows a graph view where, depending upon the link confidence level, a threshold could be applied to collapse multiple nodes into the one true entity.
One name for part of this process is entity resolution, whereby multiple data records can be associated to the same real-world entity. In contrast, a naive approach would treat each data record as a different real-world entity, resulting in up to as many so-called “entities” as there are records. If a criminal used a slightly different spelling of his name every time he left a record behind, then this naive system would never recognize them. (In analogy to adversarial schemes to thwart image recognition, criminals do this intentionally in written records, not just with straight up aliases, but with slight name tweaks to evade recognition).
Quantifind’s entity resolution is advanced because of the rich features and algorithms mentioned above that it brings to the entity resolution problem, which is especially important when the source data consists of unstructured documents where there is a lot of context available. It is also important to observe that entity resolution improves in a positive, non-linear manner with the number of sources added. For example, a third record could provide information that makes the link between the first and second records more confident, and so on. This is yet another reason that “more is better” when Quantifind accumulates multiple kinds of disparate data sets, some of which are not directly risk-relevant, but may provide the missing piece of metadata that ties an entity’s records together.
Expanding Intelligence with Disparate Sources
Importantly, the data sets in our system do not need to be structured. Quantifind specializes in structuring unstructured data sets such as news feeds with NER, then enabling those to be joined with any other data sets. Using NLP (natural language processing), other forms of metadata can be extracted from documents including role, relationships, locations, and other useful metadata.
Quantifind also brings a vast array of public data to the table, including partner data, beneficial ownership data, social data, news data, and watchlist data, both unstructured and structured. Even though our technology is valuable in connecting internal structured data sets alone, this extension to unstructured data and public data supercharges our value proposition and further expands the notion of “disparate” data as described by the DNI report.
Unlocking Applications for the Intelligence Community
Quantifind’s data set linking technology can unlock many government-specific use cases:
Criminal Investigations: Our core work enables bank investigators to accelerate customer due diligence and investigative workflows by finding entity-linked risk factors from public data, and this same technology can be effectively used by law enforcement, both for domestic and transnational crime. The techniques could also be used to effectively merge inter-agency data sets from the Department of Justice, intelligence agencies, and privately sourced data, including the suspicious activity data submitted by banks and administered by FinCEN.
Financial Service Risk: We have the ability to screen loan applicants for risk, especially during inherently fraud laden situations like the recent Small Business Administration Paycheck Protection Program (PPP) loan process, when government and bank resources are stretched thin.
Supply Chain Risk: In an increasingly globalized economy, with sanction constraints and sensitive supply chain networks, entity-linking technology will prove critical to reveal risks behind nebulous entities controlling critical components of the U.S. dependency network. By merging trade partner data sets with beneficial owner data sets and other risk-specific unstructured data, we can uncover risks from foreign-owned shell (or shelf) companies and international criminal networks. It would add insult to injury if the United States not only loses the AI race to adversarial foreign countries but also becomes a victim of large-scale schemes originating from those countries as a result.
In addition to the DNI report, most government agencies are in the process of establishing their AI strategies. The Department of Defense has stood up its Joint Artificial Intelligence Center (JAIC), and AI-specific centers of excellence are being formed to help eliminate bureaucracy and keep government capabilities as close to par with industry as possible.
Like the DNI document, these efforts are wisely grounded in pragmatic and holistic AI without getting distracted by hype. They espouse many of the principles that Quantifind also holds core to its identity: human-centric AI, interpretable algorithms for the sake of augmented intelligence and trust, a focus on quality training data and process, and continuous signal discovery.
The “data glue” technology that Quantifind can bring to the table, intelligently connecting entities and disparate data sets with confidence, is only one part of the overall mission, but a critical one. Although the government path to AI evolution will realistically lag the standards of its Silicon Valley partners, the collective mission is too important for those partners to be dissuaded from collaborative opportunities. At Quantifind, we are looking forward to extending the use cases of our technology from financial services to law enforcement, the intelligence community, and the military, by synchronizing our data and our missions.
